
Machine Learning (ML) algorithms serve as the cornerstone of data science, providing essential tools for processing and deriving meaningful insights from extensive data sets. As the year 2024 progresses, the ML algorithms landscape is undergoing continuous evolution, presenting data scientists with a multitude of options to address intricate problems. This article aims to explore the machine learning algorithms for 2024 that are currently shaping the data science industry.Machine Learning Algorithm DevelopmentOver time, there have been notable developments in the field of machine learning as algorithms have become increasingly complex and task-specific. Data scientists will have access to several algorithms in 2024, each with specific advantages and best applications.Supervised Education: An Effective Predictive ToolSupervised learning techniques continue to be an essential part of the toolbox of data scientists. By using labeled training data, these algorithms can anticipate or make conclusions based on previously unknown data. A few important supervised learning algorithms are:Linear Regression: Linear regression is utilized in forecasting and estimating outcomes based on continuous data, and it is ideal for predicting numerical values.Logistics Regression: Logistic regression is a tool that is frequently used in the medical industry for diagnostic reasons. It is used for binary classification jobs and predicts categorical outcomes.Decision Trees: These models make decisions using a tree-like structure, which is frequently shown as a flowchart with each node denoting an option.Random Forest: An ensemble approach that lessens overfitting and boosts prediction accuracy by combining many decision trees.Unsupervised Learning: Discovering Hidden PatternsAlgorithms for unsupervised learning may recognize structures and patterns in data without the requirement for labeled samples. They are very helpful for dimensionality reduction, grouping, and exploratory data analysis. Among the well-known unsupervised learning methods are:K-Means Clustering: This approach, which is frequently used in picture compression and market segmentation, divides data into clusters according to similarity.Principal Component Analysis (PCA): PCA breaks down large amounts of data into a collection of main components, which are linearly uncorrelated variables.Reinforcement Learning: Acquiring Knowledge Through InteractionReinforcement learning algorithms experiment with an environment to find the best course of action. In fields where the capacity to adjust to changing circumstances is essential, such as robots, gaming, and autonomous cars, these algorithms are at the forefront.Deep Learning: Large-Scale Neural NetworksNeural networks with numerous layers, or “deep architectures,” are used in deep learning, a type of machine learning, to model complicated patterns in data. Deep learning will still be a major force in the advancement of computer vision, speech recognition, and natural language processing in 2024.New Developments in Algorithms for Machine LearningSeveral new developments in machine learning algorithms have emerged in 2024:Graph Neural Networks (GNNs): GNNs are becoming more and more popular because of their capacity to represent data that is organized as graphs, which is helpful in recommendation systems and social network analysis.Neuro-Symbolic AI: This method builds models that can learn and reason with abstract notions by fusing neural networks and symbolic reasoning.Quantum Machine Learning: By utilizing the ideas behind quantum computing, algorithms for quantum ML stand to handle some problems far more quickly than those for conventional ML.The Future of Machine Learning AlgorithmsThe development of ML frameworks and cloud computing has made machine learning techniques more widely available and simpler to use as they continue to progress. By utilizing more sophisticated datasets, data scientists will be able to derive valuable insights that will spur innovation and decision-making in a variety of sectors by 2024.In 2024, there will be a wide range of machine learning algorithms available, providing data scientists with a strong set of tools to succeed in their line of work. The options are endless, ranging from conventional supervised and unsupervised learning to cutting-edge techniques like GNNs and quantum ML. Keeping up with these advancements will be essential for any data scientist hoping to influence the profession as it grows.

The rapid advancement in machine learning techniques and sensing devices over the past decades have opened new possibilities for the detection and tracking of objects, animals, and people. The accurate and automated detection of visual targets, also known as intelligent machine vision, can have various applications, ranging from the enhancement of security and surveillance tools to environmental monitoring and the analysis of medical imaging data.While machine vision tools have achieved highly promising results, their performance often declines in low lighting conditions or when there is limited visibility. To effectively detect and track dim targets, these tools should be able to reliably extract features such as edges and corners from images, which conventional sensors based on complementary metal-oxide-semiconductor (CMOS) technology are often unable to capture.Researchers at Nanjing University and the Chinese Academy of Sciences recently introduced a new approach to develop sensors that could better detect dim targets in complex environments. Their approach, outlined in Nature Electronics, relies on the realization of in-sensor dynamic computing, thus merging sensing and processing capabilities into a single device."In low-contrast optical environments, intelligent perception of weak targets has always faced severe challenges in terms of low accuracy and poor robustness," Shi-Jun Liang, senior author of the paper, told Tech Xplore. "This is mainly due to the small intensity difference between the target and background light signals, with the target signal almost submerged in background noise."Conventional techniques for the static pixel-independent photoelectric detection of targets in images rely on sensors based on CMOS technology. While some of these techniques have performed better than others, they often cannot accurately distinguish target signals from background signals.In recent years, computer scientists have thus been trying to devise new principles for the development of hardware based on low-dimensional materials created using mature growth and processing techniques, which are also compatible with conventional silicon-based CMOS technology. The key goal of these research efforts is to achieve higher robustness and precision in low-contrast optical environments.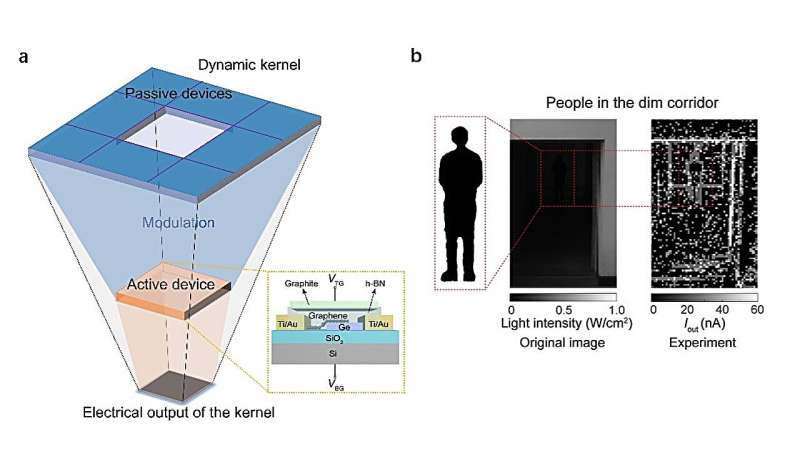 A conceptual illustration and experimental demonstration of in-sensor dynamic computing. a, Schematic of in-sensor dynamic computing using passive and active optoelectronic devices. Graphene-Ge heterostructure device with top and bottom gates used to form active pixel. b, Images of a person standing in a dim corridor obtained with camera (left), which can be regarded as a typical dim target, and processed results by the proposed computational sensor (right), demonstrating that the in-sensor dynamic computing approach can extract the edge profile. Credit: Yang et al."We have been working on the technology of in-sensor computing and published a few interesting works about optoelectronic convolutional processing, which is essentially based on static processing," Liang explained. "We asked ourselves whether we could introduce the dynamic control into the in-sensor optoelectronic computing technology to enhance the computation capability of the sensor. Building on this idea, we proposed the concept of in-sensor dynamic computing by operating the neighboring pixels in a correlated manner and demonstrated its promising application in complex lighting environments."In their recent paper, Feng Miao, Liang and their colleagues introduced a new in-sensor dynamic computing approach designed to detect and track dim targets under unfavorable lighting conditions. This approach relies on multi-terminal photoelectric devices based on graphene/germanium mixed-dimensional heterostructures, which are combined to create a single sensor."By dynamically controlling the correlation strength between adjacent devices in the optoelectronic sensor, we can realize dynamic modulation of convolution kernel weights based on local image intensity gradients and implement in-sensor dynamic computing units adaptable to image content," Miao said."Unlike the conventional sensor where the devices are independently operated, the devices in our in-sensor dynamic computing technology are correlated to detect the and track the dim targets, which enables for ultra-accurate and robust recognition of contrast-varying targets in complex lighting environments."Miao, Liang and their colleagues are the first to introduce an in-sensor computing paradigm that relies on the dynamic feedback control between interconnected and neighboring optoelectronic devices based on multi-terminal mixed-dimensional heterostructures. Initial tests found that their proposed approach is highly promising, as it enabled the robust tracking of dim tracking under unfavorable lighting conditions."Compared with conventional optoelectronic convolution whose kernel weights are constant regardless of optical image inputs, the weights of our 'dynamic kernel' are correlated to local image content, enabling the sensor more flexible, adaptable and intelligent," Miao said. "The dynamic control and correlated programming also allow convolutional neural network backpropagation approaches to be incorporated into the frontend sensor."Notably, the devices that Miao, Liang and their colleagues used to implement their approach are based on graphene and germanium, two materials that are compatible with conventional CMOS technology and can easily be produced on a large scale. In the future, the researchers' approach could be evaluated in various real-world settings, to further validate its potential."The next step for this research will be to validate the scalability of in-sensor dynamic computing through large-scale on-chip integration, and many engineering and technical issues still need to be resolved," Liang added."Extending the detection wavelength to near-infrared or even mid-infrared bands is another future research direction, which will broaden the applicability to various low-contrast scenarios such as remote sensing, medical imaging, monitoring, security and early-warning in low visibility meteorological conditions."
A conceptual illustration and experimental demonstration of in-sensor dynamic computing. a, Schematic of in-sensor dynamic computing using passive and active optoelectronic devices. Graphene-Ge heterostructure device with top and bottom gates used to form active pixel. b, Images of a person standing in a dim corridor obtained with camera (left), which can be regarded as a typical dim target, and processed results by the proposed computational sensor (right), demonstrating that the in-sensor dynamic computing approach can extract the edge profile. Credit: Yang et al."We have been working on the technology of in-sensor computing and published a few interesting works about optoelectronic convolutional processing, which is essentially based on static processing," Liang explained. "We asked ourselves whether we could introduce the dynamic control into the in-sensor optoelectronic computing technology to enhance the computation capability of the sensor. Building on this idea, we proposed the concept of in-sensor dynamic computing by operating the neighboring pixels in a correlated manner and demonstrated its promising application in complex lighting environments."In their recent paper, Feng Miao, Liang and their colleagues introduced a new in-sensor dynamic computing approach designed to detect and track dim targets under unfavorable lighting conditions. This approach relies on multi-terminal photoelectric devices based on graphene/germanium mixed-dimensional heterostructures, which are combined to create a single sensor."By dynamically controlling the correlation strength between adjacent devices in the optoelectronic sensor, we can realize dynamic modulation of convolution kernel weights based on local image intensity gradients and implement in-sensor dynamic computing units adaptable to image content," Miao said."Unlike the conventional sensor where the devices are independently operated, the devices in our in-sensor dynamic computing technology are correlated to detect the and track the dim targets, which enables for ultra-accurate and robust recognition of contrast-varying targets in complex lighting environments."Miao, Liang and their colleagues are the first to introduce an in-sensor computing paradigm that relies on the dynamic feedback control between interconnected and neighboring optoelectronic devices based on multi-terminal mixed-dimensional heterostructures. Initial tests found that their proposed approach is highly promising, as it enabled the robust tracking of dim tracking under unfavorable lighting conditions."Compared with conventional optoelectronic convolution whose kernel weights are constant regardless of optical image inputs, the weights of our 'dynamic kernel' are correlated to local image content, enabling the sensor more flexible, adaptable and intelligent," Miao said. "The dynamic control and correlated programming also allow convolutional neural network backpropagation approaches to be incorporated into the frontend sensor."Notably, the devices that Miao, Liang and their colleagues used to implement their approach are based on graphene and germanium, two materials that are compatible with conventional CMOS technology and can easily be produced on a large scale. In the future, the researchers' approach could be evaluated in various real-world settings, to further validate its potential."The next step for this research will be to validate the scalability of in-sensor dynamic computing through large-scale on-chip integration, and many engineering and technical issues still need to be resolved," Liang added."Extending the detection wavelength to near-infrared or even mid-infrared bands is another future research direction, which will broaden the applicability to various low-contrast scenarios such as remote sensing, medical imaging, monitoring, security and early-warning in low visibility meteorological conditions."

Peripheral vision enables humans to see shapes that aren’t directly in our line of sight, albeit with less detail. This ability expands our field of vision and can be helpful in many situations, such as detecting a vehicle approaching our car from the side.Unlike humans, AI does not have peripheral vision. Equipping computer vision models with this ability could help them detect approaching hazards more effectively or predict whether a human driver would notice an oncoming object.Taking a step in this direction, MIT researchers developed an image dataset that allows them to simulate peripheral vision in machine learning models. They found that training models with this dataset improved the models’ ability to detect objects in the visual periphery, although the models still performed worse than humans.Their results also revealed that, unlike with humans, neither the size of objects nor the amount of visual clutter in a scene had a strong impact on the AI’s performance.“There is something fundamental going on here. We tested so many different models, and even when we train them, they get a little bit better but they are not quite like humans. So, the question is: What is missing in these models?” says Vasha DuTell, a postdoc and co-author of a paper detailing this study.Answering that question may help researchers build machine learning models that can see the world more like humans do. In addition to improving driver safety, such models could be used to develop displays that are easier for people to view.Plus, a deeper understanding of peripheral vision in AI models could help researchers better predict human behavior, adds lead author Anne Harrington MEng ’23.“Modeling peripheral vision, if we can really capture the essence of what is represented in the periphery, can help us understand the features in a visual scene that make our eyes move to collect more information,” she explains.Their co-authors include Mark Hamilton, an electrical engineering and computer science graduate student; Ayush Tewari, a postdoc; Simon Stent, research manager at the Toyota Research Institute; and senior authors William T. Freeman, the Thomas and Gerd Perkins Professor of Electrical Engineering and Computer Science and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL); and Ruth Rosenholtz, principal research scientist in the Department of Brain and Cognitive Sciences and a member of CSAIL. The research will be presented at the International Conference on Learning Representations.“Any time you have a human interacting with a machine — a car, a robot, a user interface — it is hugely important to understand what the person can see. Peripheral vision plays a critical role in that understanding,” Rosenholtz says.Simulating peripheral visionExtend your arm in front of you and put your thumb up — the small area around your thumbnail is seen by your fovea, the small depression in the middle of your retina that provides the sharpest vision. Everything else you can see is in your visual periphery. Your visual cortex represents a scene with less detail and reliability as it moves farther from that sharp point of focus.Many existing approaches to model peripheral vision in AI represent this deteriorating detail by blurring the edges of images, but the information loss that occurs in the optic nerve and visual cortex is far more complex.For a more accurate approach, the MIT researchers started with a technique used to model peripheral vision in humans. Known as the texture tiling model, this method transforms images to represent a human’s visual information loss. They modified this model so it could transform images similarly, but in a more flexible way that doesn’t require knowing in advance where the person or AI will point their eyes.“That let us faithfully model peripheral vision the same way it is being done in human vision research,” says Harrington.The researchers used this modified technique to generate a huge dataset of transformed images that appear more textural in certain areas, to represent the loss of detail that occurs when a human looks further into the periphery.Then they used the dataset to train several computer vision models and compared their performance with that of humans on an object detection task.“We had to be very clever in how we set up the experiment so we could also test it in the machine learning models. We didn’t want to have to retrain the models on a toy task that they weren’t meant to be doing,” she says.Peculiar performanceHumans and models were shown pairs of transformed images which were identical, except that one image had a target object located in the periphery. Then, each participant was asked to pick the image with the target object.“One thing that really surprised us was how good people were at detecting objects in their periphery. We went through at least 10 different sets of images that were just too easy. We kept needing to use smaller and smaller objects,” Harrington adds.The researchers found that training models from scratch with their dataset led to the greatest performance boosts, improving their ability to detect and recognize objects. Fine-tuning a model with their dataset, a process that involves tweaking a pretrained model so it can perform a new task, resulted in smaller performance gains.But in every case, the machines weren’t as good as humans, and they were especially bad at detecting objects in the far periphery. Their performance also didn’t follow the same patterns as humans.“That might suggest that the models aren’t using context in the same way as humans are to do these detection tasks. The strategy of the models might be different,” Harrington says.The researchers plan to continue exploring these differences, with a goal of finding a model that can predict human performance in the visual periphery. This could enable AI systems that alert drivers to hazards they might not see, for instance. They also hope to inspire other researchers to conduct additional computer vision studies with their publicly available dataset.“This work is important because it contributes to our understanding that human vision in the periphery should not be considered just impoverished vision due to limits in the number of photoreceptors we have, but rather, a representation that is optimized for us to perform tasks of real-world consequence,” says Justin Gardner, an associate professor in the Department of Psychology at Stanford University who was not involved with this work. “Moreover, the work shows that neural network models, despite their advancement in recent years, are unable to match human performance in this regard, which should lead to more AI research to learn from the neuroscience of human vision. This future research will be aided significantly by the database of images provided by the authors to mimic peripheral human vision.”

Imagine yourself glancing at a busy street for a few moments, then trying to sketch the scene you saw from memory. Most people could draw the rough positions of the major objects like cars, people, and crosswalks, but almost no one can draw every detail with pixel-perfect accuracy. The same is true for most modern computer vision algorithms: They are fantastic at capturing high-level details of a scene, but they lose fine-grained details as they process information.Now, MIT researchers have created a system called “FeatUp” that lets algorithms capture all of the high- and low-level details of a scene at the same time — almost like Lasik eye surgery for computer vision.When computers learn to “see” from looking at images and videos, they build up “ideas” of what's in a scene through something called “features.” To create these features, deep networks and visual foundation models break down images into a grid of tiny squares and process these squares as a group to determine what's going on in a photo. Each tiny square is usually made up of anywhere from 16 to 32 pixels, so the resolution of these algorithms is dramatically smaller than the images they work with. In trying to summarize and understand photos, algorithms lose a ton of pixel clarity. The FeatUp algorithm can stop this loss of information and boost the resolution of any deep network without compromising on speed or quality. This allows researchers to quickly and easily improve the resolution of any new or existing algorithm. For example, imagine trying to interpret the predictions of a lung cancer detection algorithm with the goal of localizing the tumor. Applying FeatUp before interpreting the algorithm using a method like class activation maps (CAM) can yield a dramatically more detailed (16-32x) view of where the tumor might be located according to the model. Play videoVideo: Mark HamiltonFeatUp not only helps practitioners understand their models, but also can improve a panoply of different tasks like object detection, semantic segmentation (assigning labels to pixels in an image with object labels), and depth estimation. It achieves this by providing more accurate, high-resolution features, which are crucial for building vision applications ranging from autonomous driving to medical imaging.“The essence of all computer vision lies in these deep, intelligent features that emerge from the depths of deep learning architectures. The big challenge of modern algorithms is that they reduce large images to very small grids of 'smart' features, gaining intelligent insights but losing the finer details,” says Mark Hamilton, an MIT PhD student in electrical engineering and computer science, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) affiliate, and a co-lead author on a paper about the project. “FeatUp helps enable the best of both worlds: highly intelligent representations with the original image’s resolution. These high-resolution features significantly boost performance across a spectrum of computer vision tasks, from enhancing object detection and improving depth prediction to providing a deeper understanding of your network's decision-making process through high-resolution analysis.” Resolution renaissance As these large AI models become more and more prevalent, there’s an increasing need to explain what they’re doing, what they’re looking at, and what they’re thinking. But how exactly can FeatUp discover these fine-grained details? Curiously, the secret lies in wiggling and jiggling images. In particular, FeatUp applies minor adjustments (like moving the image a few pixels to the left or right) and watches how an algorithm responds to these slight movements of the image. This results in hundreds of deep-feature maps that are all slightly different, which can be combined into a single crisp, high-resolution, set of deep features. “We imagine that some high-resolution features exist, and that when we wiggle them and blur them, they will match all of the original, lower-resolution features from the wiggled images. Our goal is to learn how to refine the low-resolution features into high-resolution features using this 'game' that lets us know how well we are doing,” says Hamilton. This methodology is analogous to how algorithms can create a 3D model from multiple 2D images by ensuring that the predicted 3D object matches all of the 2D photos used to create it. In FeatUp’s case, they predict a high-resolution feature map that’s consistent with all of the low-resolution feature maps formed by jittering the original image.The team notes that standard tools available in PyTorch were insufficient for their needs, and introduced a new type of deep network layer in their quest for a speedy and efficient solution. Their custom layer, a special joint bilateral upsampling operation, was over 100 times more efficient than a naive implementation in PyTorch. The team also showed this new layer could improve a wide variety of different algorithms including semantic segmentation and depth prediction. This layer improved the network’s ability to process and understand high-resolution details, giving any algorithm that used it a substantial performance boost. “Another application is something called small object retrieval, where our algorithm allows for precise localization of objects. For example, even in cluttered road scenes algorithms enriched with FeatUp can see tiny objects like traffic cones, reflectors, lights, and potholes where their low-resolution cousins fail. This demonstrates its capability to enhance coarse features into finely detailed signals,” says Stephanie Fu ’22, MNG ’23, a PhD student at the University of California at Berkeley and another co-lead author on the new FeatUp paper. “This is especially critical for time-sensitive tasks, like pinpointing a traffic sign on a cluttered expressway in a driverless car. This can not only improve the accuracy of such tasks by turning broad guesses into exact localizations, but might also make these systems more reliable, interpretable, and trustworthy.”What next?Regarding future aspirations, the team emphasizes FeatUp’s potential widespread adoption within the research community and beyond, akin to data augmentation practices. “The goal is to make this method a fundamental tool in deep learning, enriching models to perceive the world in greater detail without the computational inefficiency of traditional high-resolution processing,” says Fu.“FeatUp represents a wonderful advance towards making visual representations really useful, by producing them at full image resolutions,” says Cornell University computer science professor Noah Snavely, who was not involved in the research. “Learned visual representations have become really good in the last few years, but they are almost always produced at very low resolution — you might put in a nice full-resolution photo, and get back a tiny, postage stamp-sized grid of features. That’s a problem if you want to use those features in applications that produce full-resolution outputs. FeatUp solves this problem in a creative way by combining classic ideas in super-resolution with modern learning approaches, leading to beautiful, high-resolution feature maps.”“We hope this simple idea can have broad application. It provides high-resolution versions of image analytics that we’d thought before could only be low-resolution,” says senior author William T. Freeman, an MIT professor of electrical engineering and computer science professor and CSAIL member.
Play videoVideo: Mark HamiltonFeatUp not only helps practitioners understand their models, but also can improve a panoply of different tasks like object detection, semantic segmentation (assigning labels to pixels in an image with object labels), and depth estimation. It achieves this by providing more accurate, high-resolution features, which are crucial for building vision applications ranging from autonomous driving to medical imaging.“The essence of all computer vision lies in these deep, intelligent features that emerge from the depths of deep learning architectures. The big challenge of modern algorithms is that they reduce large images to very small grids of 'smart' features, gaining intelligent insights but losing the finer details,” says Mark Hamilton, an MIT PhD student in electrical engineering and computer science, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) affiliate, and a co-lead author on a paper about the project. “FeatUp helps enable the best of both worlds: highly intelligent representations with the original image’s resolution. These high-resolution features significantly boost performance across a spectrum of computer vision tasks, from enhancing object detection and improving depth prediction to providing a deeper understanding of your network's decision-making process through high-resolution analysis.” Resolution renaissance As these large AI models become more and more prevalent, there’s an increasing need to explain what they’re doing, what they’re looking at, and what they’re thinking. But how exactly can FeatUp discover these fine-grained details? Curiously, the secret lies in wiggling and jiggling images. In particular, FeatUp applies minor adjustments (like moving the image a few pixels to the left or right) and watches how an algorithm responds to these slight movements of the image. This results in hundreds of deep-feature maps that are all slightly different, which can be combined into a single crisp, high-resolution, set of deep features. “We imagine that some high-resolution features exist, and that when we wiggle them and blur them, they will match all of the original, lower-resolution features from the wiggled images. Our goal is to learn how to refine the low-resolution features into high-resolution features using this 'game' that lets us know how well we are doing,” says Hamilton. This methodology is analogous to how algorithms can create a 3D model from multiple 2D images by ensuring that the predicted 3D object matches all of the 2D photos used to create it. In FeatUp’s case, they predict a high-resolution feature map that’s consistent with all of the low-resolution feature maps formed by jittering the original image.The team notes that standard tools available in PyTorch were insufficient for their needs, and introduced a new type of deep network layer in their quest for a speedy and efficient solution. Their custom layer, a special joint bilateral upsampling operation, was over 100 times more efficient than a naive implementation in PyTorch. The team also showed this new layer could improve a wide variety of different algorithms including semantic segmentation and depth prediction. This layer improved the network’s ability to process and understand high-resolution details, giving any algorithm that used it a substantial performance boost. “Another application is something called small object retrieval, where our algorithm allows for precise localization of objects. For example, even in cluttered road scenes algorithms enriched with FeatUp can see tiny objects like traffic cones, reflectors, lights, and potholes where their low-resolution cousins fail. This demonstrates its capability to enhance coarse features into finely detailed signals,” says Stephanie Fu ’22, MNG ’23, a PhD student at the University of California at Berkeley and another co-lead author on the new FeatUp paper. “This is especially critical for time-sensitive tasks, like pinpointing a traffic sign on a cluttered expressway in a driverless car. This can not only improve the accuracy of such tasks by turning broad guesses into exact localizations, but might also make these systems more reliable, interpretable, and trustworthy.”What next?Regarding future aspirations, the team emphasizes FeatUp’s potential widespread adoption within the research community and beyond, akin to data augmentation practices. “The goal is to make this method a fundamental tool in deep learning, enriching models to perceive the world in greater detail without the computational inefficiency of traditional high-resolution processing,” says Fu.“FeatUp represents a wonderful advance towards making visual representations really useful, by producing them at full image resolutions,” says Cornell University computer science professor Noah Snavely, who was not involved in the research. “Learned visual representations have become really good in the last few years, but they are almost always produced at very low resolution — you might put in a nice full-resolution photo, and get back a tiny, postage stamp-sized grid of features. That’s a problem if you want to use those features in applications that produce full-resolution outputs. FeatUp solves this problem in a creative way by combining classic ideas in super-resolution with modern learning approaches, leading to beautiful, high-resolution feature maps.”“We hope this simple idea can have broad application. It provides high-resolution versions of image analytics that we’d thought before could only be low-resolution,” says senior author William T. Freeman, an MIT professor of electrical engineering and computer science professor and CSAIL member.
Lead authors Fu and Hamilton are accompanied by MIT PhD students Laura Brandt SM ’21 and Axel Feldmann SM ’21, as well as Zhoutong Zhang SM ’21, PhD ’22, all current or former affiliates of MIT CSAIL. Their research is supported, in part, by a National Science Foundation Graduate Research Fellowship, by the National Science Foundation and Office of the Director of National Intelligence, by the U.S. Air Force Research Laboratory, and by the U.S. Air Force Artificial Intelligence Accelerator. The group will present their work in May at the International Conference on Learning Representations.

I. IntroductionThe past 18 months have ushered in tremendous change that is disrupting the very nature of work. Generative Artificial Intelligence (GenAI), Large Language Models (LLMs), and foundation models have become ubiquitous in vernacular. These models, containing billions of parameters and trained on massive amounts of data using self-supervised methods, are performing complex natural language tasks and exhibiting more generalized intelligence compared to earlier models [i][ii]; fueling unparallel productivity gains across diverse industries through numerous use cases such as personalized customer care and self-service [iii], knowledge management [iv] and content creation [v], research and development [vi], fraud detection [vii][viii], language translation [ix], and even forecasting of life expectancy [x].Closely following in this wake are emerging developments in computer vision methods and approaches. At the forefront of this shift are advancements in vision transformer (ViT) architectures that are propelling computer vision capabilities into unprecedented levels of sophistication. Awareness of the rapid development and maturation of these capabilities is crucial to navigating the rapidly evolving AI landscape. Now, more than ever, defense leaders need to understand and harness these capabilities within Processing, Exploitation, and Dissemination (PED) and mission planning workflows to enable sensemaking at scale.II. Rise of the Vision Transformer ArchitectureConvolutional neural networks (CNNs) [xi] have traditionally held dominance within computer vision, demonstrating high performance on common tasks such as image classification, object detection, and segmentation. However, training such models requires significant amounts of labeled data for supervised learning, a highly labor-intensive task that is challenging to scale and slow to adapt to dynamic changes in the environment or requirements. Furthermore, the labeled datasets that do exist in the public domain may frequently be unsuitable to the unique use cases and/or imagery types that exist within the national security domain.Recent years have seen the inception of the ViT architecture as a leading contender in the computer vision arena. The power of ViTs is in their ability to decompose images into fixed size patches and encode these fragments into a linear sequence of embeddings that capture semantic representations, similar to a sentence that describes the image. The ViT then sequentially understands each fragment, applying multi-head self-attention to recognize patterns and capture relationships globally across all fragments, to build a coherent understanding of the image [xii].This results in several benefits over CNNs. First and foremost, ViTs are shown to demonstrate performance that matches or exceeds the state of the art compared to CNNs on many image classification datasets when trained on large quantities of data (e.g., 14 million — 300 million images). This level of performance is achieved while requiring 2–4 times less compute to train. In addition, ViTs can natively handle images of varying dimension due to their ability to process arbitrary sequence lengths (within memory constraints). Lastly, ViTs can capture long-range dependencies between inputs and provide enhanced scalability over CNNs. ViTs do have some limitations in comparison to CNNs. ViTs are unable to generalize well when trained on insufficient data due to lacking strong inductive biases, such as translation equivariance and locality. As a result, CNNs outperform ViTs on smaller datasets. However, when considering the scaling challenges present within the Department of Defense (DoD), ViTs show promise as an architecture to lead in this space.2023 saw several computer vision advances leveraging ViT architectures. While in no way exhaustive, four models that highlight the rapid evolution of computer vision are Distillation of Knowledge with No Labels Version 2 (DINOv2), the Segment Anything Model (SAM), the Joint-Embedding Predictive Architecture (JEPA), and the Prithvi geospatial foundation model.DINOv2 [xiii] leverages two concepts that advanced computer vision. The first concept is that of self-supervised learning of visual features directly from images, removing the need for large quantities of labels to support model training. Central to this approach is DINOv2’s data processing pipeline, which clusters images from a large uncurated dataset with images from a smaller curated dataset through a self-supervised retrieval system. This process results in the ability to create a large augmented curated dataset without a drop in quality, a key hurdle that must be crossed in scaling image foundation models. Additionally, DINOv2 employs a teacher-student distillation method to transfer knowledge from a large model to smaller models. At a high level, this approach works by freezing the weights of the large model with the goal of minimizing the differences between the embeddings coming from the smaller models with that of the larger model. This method is shown to achieve better performance than attempting to train smaller models directly on the data. Once trained, DINOv2 learned features demonstrate very good transferability across domains and the ability understand relations between similar parts of different objects. This results in an image foundation model whose outputs can be used by multiple downstream models for specific tasks.SAM [xiv] is an image segmentation foundation model capable of promptable zero-shot segmentation of unfamiliar objects and images, without the need for additional training. This is accomplished through an architecture with three components: a ViT image encoder, a prompt encoder able to support both sparse (e.g., points, boxes, text) and dense (i.e., mask) prompts, and a fast mask decoder that efficiently maps the image embedding, prompt embeddings, and an output token to an autogenerated image mask. SAM is not without limitations as it requires large-scale supervised training, can miss fine structures, suffer from minor hallucinations, and may not produce boundaries as crisp as other methods. However, initial efforts present opportunity to address mission use cases that require the ability to segment objects in imagery.Originally adapted to image tasks, JEPA [xv] is the first computer vision architecture designed to address critical shortcomings in existing ML systems needed to reach human levels of learning and understanding of the external world [xvi]. JEPA attempts to overcome limitations with current self-supervised learning methods (e.g., invariance-based methods, generative methods) through predicting missing image information in an abstract representation space. In practice, this is performed by predicting the representations (e.g., embeddings) of various target blocks (e.g., tail, legs, ears) in an image based on being provided a single context block (e.g., body and head of a dog). By predicting semantic representations of target blocks, without explicitly predicting the image pixels, JEPA is able to more closely replicate how humans predict missing parts of an image. More importantly, JEPA’s performance is comparable with invariance-based methods on semantic tasks, performs better on low-level vision tasks (e.g., object counting), and demonstrates high scalability and computational efficiency. This model architecture is continuing to be advanced with the introduction of latent variable energy-based models [xvii] to achieve multimodal predictions in high-dimensional problems with significant uncertainty (e.g., autonomous system navigation) and has recently been adapted to video [xviii].Lastly, IBM, through a public/private partnership involving NASA and IBM Research, developed the first open-source geospatial foundation model for remote sensing data called Prithvi [xix]. Model development leveraged a First-of-a-Kind framework to build a representative dataset of raw multi-temporal and multi-spectral satellite images that avoided biases toward the most common geospatial features and removed noise from cloud cover or missing data from sensor malfunctions. This dataset was then used for self-supervised foundation model pretraining using an encoder-decoder architecture based on the masked autoencoder (MAE) [xx] approach. Prithvi was subsequently fined tuned using a small set of labeled images for specific downstream tasks, such as multi-temporal cloud imputation, flood mapping, fire-scar segmentation, and multi-temporal crop segmentation. Importantly, Prithvi is shown to generalize to different resolutions and geographic regions from the entire globe using a few labeled data during fine-tuning and is being used to convert NASA’s satellite observations into customized maps of natural disasters and other environmental changes.III. Rapid Evolution: AI Trends in Flux2023 also introduced the convergence of LLMs and ViTs (along with other modes) into Large Multimodal Models (LMMs), also referred to as vision language models (VLM) or multimodal large language models (MLLM). The strength of these models lies in their ability to combine the understanding of text with the interpretation of visual data [xxi]. However, this is not without challenges as training large multimodal models in an end-to-end manner would be immensely costly and risk catastrophic forgetting. In practice, training such models generally involves a learnable interface between a pre-trained visual encoder and an LLM [xxii].Several influential models were released, to include Google’s PALM-E [xxiii] robotics vision-language model with state-of-the-art performance on the Outside Knowledge Visual Question Answering (OK-VQA) benchmark without task-specific fine tuning and the recently released Gemini [xxiv] family of models, trained multimodally over videos, text, and images. In addition, Meta released ImageBind [xxv], an LMM that learns a joint embedding across six different modalities (i.e., images, text, audio, depth perception, thermal, and inertial measurement unit (IMU) data). Two models, in particular, highlight the rapid evolution in this space.The first of these is Apple’s Ferret [xxvi] model, which can address the problem of enabling spatial understanding in vision-language learning. It does so through unified learning of referring (the ability to understand the semantics of a specific point or region in an image) and grounding (the process of using LLMs with relevant, use-case specific external information) capabilities within large multimodal models. This model elevates multimodal vision and language capabilities one step closer to the way humans process the world through seamless integration of referring and grounding capabilities with dialogue and reasoning. To achieve results, Ferret was trained via GRIT, a Ground-and-Refer Instruction-Tuning dataset with 1.1M samples including grounding (i.e., text-in location-out), referring (location-in text-out), and mixed (text/location-in text/location-out) data covering multiple levels of spatial knowledge. The model was then evaluated on tasks jointly requiring referring/grounding, semantics, knowledge, and reasoning, demonstrating superior performance when evaluated on conventional referring and grounding tasks while reducing object hallucinations.The second of these is Large Language and Vision Assistants that Plug and Learn to Use Skills (LLaVA-Plus) [xxvii], a general-purpose multimodal assistant that was released in late 2023 and built upon the initial LLaVA [xxviii] model released earlier in the year. The design of LLaVA-Plus was influenced by the Society of Mind theory of natural intelligence [xxix], in which emergent capabilities arise from combination of individual task or skill specific tools. The modularized system architecture presents a novel approach that allows an LMM, operating as a planner, to learn a wide range of skills. This enables the expansion of capabilities and interfaces at scale through leveraging a repository of vision and vision-language specialist models as tools for use when needed. This facilitates not only user-oriented dialogues, where the model immediately responds to user instruction using innate knowledge, but also skill-oriented dialogues where the LMM can initiate requests to call the appropriate specialist model in response to an instruction to accomplish a task. While there are limitations due to hallucinations and tool use conflicts in practice, LLaVA-Plus is an innovative step to new methods for human-computer teaming through multimodal AI agents.Lastly, as exciting as these developments are, one would be remiss without mentioning experimentation with emerging architectures that have the potential to revolutionize the field some more. The first architecture is the Rententive Network [xxx] (RetNet), a novel architecture that is a candidate to supersede the transformer as the dominant architecture for computer vision, language, and multimodal foundation models. RetNets demonstrate benefits seen in transformers and recurrent neural networks, without some of the drawbacks of each. These include training parallelism, low cost inference, and transformer-comparable performance with efficient long-sequence modeling. RetNets substitute conventional multi-head attention, used within transformers, with a multi-scale retention mechanism that is able to fully utilize GPUs and enable efficient O(1) inference in terms of memory and compute.The second is the recently released Mixtral 8x7B [xxxi] model, a decoder-only Sparse Mixture of Experts (SMoE) language model where each layer of the model is composed of eight feedforward blocks that act as experts. This novel architecture achieves faster inference speeds with superior cost-performance, using only 13B active parameters for each token at inference. It does so through an approach where each token is evaluated by two experts at a given timestep. However, these two experts can vary at each timestep, enabling each token to access the full sparse parameter count at 47B parameters. Of note, the model retains a higher memory cost that is proportional to the sparse parameter count. This model architecture confers tremendous benefits. At one tenth of the parameters, Mixtral 8x7B is able to match or exceed the performance of LLAMA 2 70B and GPT-3.5 (175B parameters) on most benchmarks. In addition, the cost efficiencies of this model are conducive to deployment and inference on tactical infrastructure, where compute, size, and weight constraints are a factor.Although diverse and developed to accomplish different tasks, the models covered here illustrate the many innovation pathways that are being traversed in advancing AI capabilities. Of note, are the difference model classes (e.g., encoder only, encoder-decoder, decoder only) that are employed across the various models. A future effort may be to explore if there are performance benefits or tradeoffs due to class based on the task.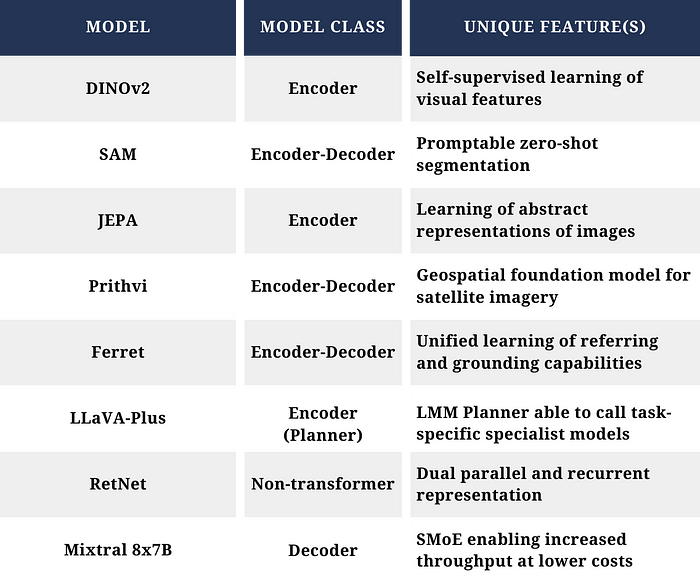 Characteristics of Select Surveyed ModelsAs these capabilities continue to mature, we will likely see a combining of features within models as certain features become expectations for performance. There will also be a shift towards creation of a multi-model ecosystem in recognition that one size does not fit all. Instead, AI agents acting as planners, orchestrators, and teammates will collaborate to dynamically select the best specialist model or tool for the task based on use case or Persona of Query driven needs [xxxii].IV. Challenges and RisksWhile the previous survey of model advancements helps illustrate the increasing rate of change within this field spurred by advancements in generative AI and foundation models, there are several challenges that cannot be overlooked as Federal organizations consider how to employ these capabilities. For the purposes of this section, we reference research primarily addressing LLMs. This was a deliberate choice to highlight risks inherent to models that leverage the autoregressive transformer architecture.First, is the issue of resource constraints, both for enterprise training and inferencing of models and for model training and inferencing at the edge. The rise of ever larger AI models encompassing multiple billions of parameters is leading to strained resources due to infrastructure costs for compute, specialized AI talent needed to implement capabilities, and the challenges associated with amassing, curating, and training on the colossal data volumes required for such models. Such challenges can translate into financial shocks to organizational budgets that may have been set in the years prior due to the need to run high performance servers equipped with GPUs or attract and retain top AI talent. Additionally, there is an increasing need to perform training, retraining, and inferencing of models at the edge to support the processing, exploitation, and dissemination of detections of multimodal data. This requires the ability to run models on smaller hardware (e.g., human packable devices, onboard autonomous systems or sensors), where size, weight, and power are significant considerations.The second of these is the issue of trustworthiness. To rely on generative AI and foundation models within mission critical workflows, one must be able to trust the output of such models. As such, the trustworthiness of models is of paramount concern. Much of the discourse on this topic has focused on hallucinations within the output, as well as attempts to define a broad set of dimensions against which to measure trustworthiness [xxxiii][xxxiv]. While these are valid concerns, trustworthiness extends beyond these dimensions to also include ensuring that the model arrives at the best possible outcome based on the latest corpus of data and training. One must be able to trust that the outcome is a global maximum in terms of suitability for the task, as opposed to a local maximum, which could have real world impacts if embedded into a mission critical workflow.Third, and likely the most daunting, is that of security and privacy. To be able to leverage generative AI within Federal environments, one must be able to do so without compromise to the network and the data that resides on that network. Research has shown that LLMs can pose risks to security and privacy and such vulnerabilities can be grouped into AI model inherent vulnerabilities (e.g., data poisoning backdoor attacks, training data extraction) and non-AI model inherent vulnerabilities (e.g., remote code execution, prompt injection, side channel attacks). To date, LLMs have been predominantly used in user level attacks such as disinformation, misinformation, and social engineering [xxxv], although new attacks continue to appear. For example, it has been shown that one can train deceptive LLMs able to switch their behavior from trusted to malicious in response to external events or triggers, eluding initial risk evaluation and creating a false sense of trust before attacking [xxxvi]. In addition, 2024 heralded the creation of AI worms [xxxvii] that can steal data and spread malware and spam. Such an attack uses an adversarial self-replicating prompt embedded within multimodal media files (e.g., text, image, audio) to effectively jailbreak and task the target LLM. Should future LLM/LMMs be given access to operating system and hardware-level functions, then threats from these vectors could escalate dramatically.These challenges aren’t without opportunities. NIST recently released the inaugural version of its Artificial Intelligence Risk Management Framework [xxxviii] to aid with mitigating the risks related to AI. However, the nascent nature of this field means that much still remains unknown. Couple this with the fact that rigidity and bureaucracy within the RMF process means that, in some cases, by the time technology is approved for use and operationalized, it may be one or two generations behind state-of-the-art capabilities. Organizations face a challenge of how do they operationalize technology using a process that may take 9–12 months to complete when that same technology may be surpassed within six months.V. Human-AI Collaboration: Redefining the WorkforceAs AI trends continue to advance, this will have a profound impact on the dynamics of the workforce. Collaboration between humans and AI systems will become the norm as those who are able and willing to partner with AI will experience increased efficiency, innovation, and effectiveness. Supported by autonomous or semi-autonomous actions by AI agents [xxxix], human-AI teams will reshape how we make sense of and interact with the world.AI will also play a pivotal role in transforming job roles and skill requirements. The workforce will need to adapt to this shift by acquiring new skills and competencies that complement, not compete with, AI’s capabilities and strengths. There will be a growing need for professionals who can effectively manage and collaborate with AI systems and other human-AI teams, increasing the demand for soft skills such as emotional intelligence, critical thinking, and creativity.This evolution in skill sets will require changes in organizational talent programs to ensure training of the incoming workforce aligns to near-term and long-term organizational needs in AI. In addition to focusing on incoming professionals, organizations must prioritize upskilling and reskilling of the existing workforce to move the organization as a whole through the transformation journey to embrace this new AI era. While not covered in depth in this article, this topic is one that must be carefully considered to promote AI adoption in ways that take into account ethical considerations and ensure that AI systems are designed and implemented responsibly.VI. Future Outlook and RecommendationsThe pace of technological change will continue to accelerate over the next 18-month horizon. The precise path of this change is unpredictable, as each advancing month gives way to new developments that reframe the world’s understanding of the art of the possible. As breathtaking as some recent capabilities are, these technologies are still in a nascent stage. To have business and mission value, the maturation and commercialization of generative AI capabilities must continue, which will take some time.In addition, Generative AI remains experimental and has not yet been operationalized for critical mission application. As organizations consider how to move forward with using the tremendous power of generative AI and foundation models, any strategy must be based upon a High OPTEMPO Concurrency where one is simultaneously experimenting with the newest technology, developing and training on a continuous basis in the mode of “Always in a State of Becoming” [xl]. To do so, organizations must be willing to accept additional risk, but also make use of emerging technologies to modernize existing methods. For example, LLMs have been shown to identify security vulnerabilities in code with greater effectiveness than leading commercial tools using traditional methods. Such methods can be used to enhance speed and efficacy in detecting vulnerable and malicious code as part of the RMF process [xli].Posturing oneself to capitalize on AI advancements, especially in the realm of computer vision, necessitates that leaders within the organization become versed and remain current on rapidly progressing developments in AI. As part of their strategy, organizations should consider how to invest in the infrastructure and data foundation that will enable an AI-first future. This includes building modern data architectures and approaches to facilitate the rapid exchange of information as well as machine manipulation of data and services required to support automated discovery, understanding, and actions on the data. Moreover, organizations need to begin regular experimentation now in order to build the organizational capacity and learning needed for the future.VII. ConclusionAs we progress through the remainder of the year, the trajectory of technological advancement is poised to surge into uncharted realms of what’s possible with AI. The advent of increasingly intricate multimodal models will revolutionize human-AI collaboration. Interactive analysis and interrogation of multimodal data, coupled with autonomous or semi-autonomous actions by AI agents and heightened reasoning capabilities derived from models able to create internal representations of the external world, will redefine operational landscapes.The imperative to wield these capabilities to understand and decipher vast pools of visual and multimodal data, critical to national security, will define the latter half of this decade. Navigating this transformative era necessitates a forward-thinking mindset, the courage to increase one’s risk appetite, and the resilience to shape organizational strategy and policy to capitalize on the coming wave of change. As such, leaders must adopt a proactive stance in integrating AI, while placing an emphasis on its responsible deployment. Doing so will enable organizations to harness the full potential of evolving AI technologies.
Characteristics of Select Surveyed ModelsAs these capabilities continue to mature, we will likely see a combining of features within models as certain features become expectations for performance. There will also be a shift towards creation of a multi-model ecosystem in recognition that one size does not fit all. Instead, AI agents acting as planners, orchestrators, and teammates will collaborate to dynamically select the best specialist model or tool for the task based on use case or Persona of Query driven needs [xxxii].IV. Challenges and RisksWhile the previous survey of model advancements helps illustrate the increasing rate of change within this field spurred by advancements in generative AI and foundation models, there are several challenges that cannot be overlooked as Federal organizations consider how to employ these capabilities. For the purposes of this section, we reference research primarily addressing LLMs. This was a deliberate choice to highlight risks inherent to models that leverage the autoregressive transformer architecture.First, is the issue of resource constraints, both for enterprise training and inferencing of models and for model training and inferencing at the edge. The rise of ever larger AI models encompassing multiple billions of parameters is leading to strained resources due to infrastructure costs for compute, specialized AI talent needed to implement capabilities, and the challenges associated with amassing, curating, and training on the colossal data volumes required for such models. Such challenges can translate into financial shocks to organizational budgets that may have been set in the years prior due to the need to run high performance servers equipped with GPUs or attract and retain top AI talent. Additionally, there is an increasing need to perform training, retraining, and inferencing of models at the edge to support the processing, exploitation, and dissemination of detections of multimodal data. This requires the ability to run models on smaller hardware (e.g., human packable devices, onboard autonomous systems or sensors), where size, weight, and power are significant considerations.The second of these is the issue of trustworthiness. To rely on generative AI and foundation models within mission critical workflows, one must be able to trust the output of such models. As such, the trustworthiness of models is of paramount concern. Much of the discourse on this topic has focused on hallucinations within the output, as well as attempts to define a broad set of dimensions against which to measure trustworthiness [xxxiii][xxxiv]. While these are valid concerns, trustworthiness extends beyond these dimensions to also include ensuring that the model arrives at the best possible outcome based on the latest corpus of data and training. One must be able to trust that the outcome is a global maximum in terms of suitability for the task, as opposed to a local maximum, which could have real world impacts if embedded into a mission critical workflow.Third, and likely the most daunting, is that of security and privacy. To be able to leverage generative AI within Federal environments, one must be able to do so without compromise to the network and the data that resides on that network. Research has shown that LLMs can pose risks to security and privacy and such vulnerabilities can be grouped into AI model inherent vulnerabilities (e.g., data poisoning backdoor attacks, training data extraction) and non-AI model inherent vulnerabilities (e.g., remote code execution, prompt injection, side channel attacks). To date, LLMs have been predominantly used in user level attacks such as disinformation, misinformation, and social engineering [xxxv], although new attacks continue to appear. For example, it has been shown that one can train deceptive LLMs able to switch their behavior from trusted to malicious in response to external events or triggers, eluding initial risk evaluation and creating a false sense of trust before attacking [xxxvi]. In addition, 2024 heralded the creation of AI worms [xxxvii] that can steal data and spread malware and spam. Such an attack uses an adversarial self-replicating prompt embedded within multimodal media files (e.g., text, image, audio) to effectively jailbreak and task the target LLM. Should future LLM/LMMs be given access to operating system and hardware-level functions, then threats from these vectors could escalate dramatically.These challenges aren’t without opportunities. NIST recently released the inaugural version of its Artificial Intelligence Risk Management Framework [xxxviii] to aid with mitigating the risks related to AI. However, the nascent nature of this field means that much still remains unknown. Couple this with the fact that rigidity and bureaucracy within the RMF process means that, in some cases, by the time technology is approved for use and operationalized, it may be one or two generations behind state-of-the-art capabilities. Organizations face a challenge of how do they operationalize technology using a process that may take 9–12 months to complete when that same technology may be surpassed within six months.V. Human-AI Collaboration: Redefining the WorkforceAs AI trends continue to advance, this will have a profound impact on the dynamics of the workforce. Collaboration between humans and AI systems will become the norm as those who are able and willing to partner with AI will experience increased efficiency, innovation, and effectiveness. Supported by autonomous or semi-autonomous actions by AI agents [xxxix], human-AI teams will reshape how we make sense of and interact with the world.AI will also play a pivotal role in transforming job roles and skill requirements. The workforce will need to adapt to this shift by acquiring new skills and competencies that complement, not compete with, AI’s capabilities and strengths. There will be a growing need for professionals who can effectively manage and collaborate with AI systems and other human-AI teams, increasing the demand for soft skills such as emotional intelligence, critical thinking, and creativity.This evolution in skill sets will require changes in organizational talent programs to ensure training of the incoming workforce aligns to near-term and long-term organizational needs in AI. In addition to focusing on incoming professionals, organizations must prioritize upskilling and reskilling of the existing workforce to move the organization as a whole through the transformation journey to embrace this new AI era. While not covered in depth in this article, this topic is one that must be carefully considered to promote AI adoption in ways that take into account ethical considerations and ensure that AI systems are designed and implemented responsibly.VI. Future Outlook and RecommendationsThe pace of technological change will continue to accelerate over the next 18-month horizon. The precise path of this change is unpredictable, as each advancing month gives way to new developments that reframe the world’s understanding of the art of the possible. As breathtaking as some recent capabilities are, these technologies are still in a nascent stage. To have business and mission value, the maturation and commercialization of generative AI capabilities must continue, which will take some time.In addition, Generative AI remains experimental and has not yet been operationalized for critical mission application. As organizations consider how to move forward with using the tremendous power of generative AI and foundation models, any strategy must be based upon a High OPTEMPO Concurrency where one is simultaneously experimenting with the newest technology, developing and training on a continuous basis in the mode of “Always in a State of Becoming” [xl]. To do so, organizations must be willing to accept additional risk, but also make use of emerging technologies to modernize existing methods. For example, LLMs have been shown to identify security vulnerabilities in code with greater effectiveness than leading commercial tools using traditional methods. Such methods can be used to enhance speed and efficacy in detecting vulnerable and malicious code as part of the RMF process [xli].Posturing oneself to capitalize on AI advancements, especially in the realm of computer vision, necessitates that leaders within the organization become versed and remain current on rapidly progressing developments in AI. As part of their strategy, organizations should consider how to invest in the infrastructure and data foundation that will enable an AI-first future. This includes building modern data architectures and approaches to facilitate the rapid exchange of information as well as machine manipulation of data and services required to support automated discovery, understanding, and actions on the data. Moreover, organizations need to begin regular experimentation now in order to build the organizational capacity and learning needed for the future.VII. ConclusionAs we progress through the remainder of the year, the trajectory of technological advancement is poised to surge into uncharted realms of what’s possible with AI. The advent of increasingly intricate multimodal models will revolutionize human-AI collaboration. Interactive analysis and interrogation of multimodal data, coupled with autonomous or semi-autonomous actions by AI agents and heightened reasoning capabilities derived from models able to create internal representations of the external world, will redefine operational landscapes.The imperative to wield these capabilities to understand and decipher vast pools of visual and multimodal data, critical to national security, will define the latter half of this decade. Navigating this transformative era necessitates a forward-thinking mindset, the courage to increase one’s risk appetite, and the resilience to shape organizational strategy and policy to capitalize on the coming wave of change. As such, leaders must adopt a proactive stance in integrating AI, while placing an emphasis on its responsible deployment. Doing so will enable organizations to harness the full potential of evolving AI technologies.

A new field promises to usher in a new era of using machine learning and computer vision to tackle small and large-scale questions about the biology of organisms around the globe.The field of imageomics aims to help explore fundamental questions about biological processes on Earth by combining images of living organisms with computer-enabled analysis and discovery. Wei-Lun Chao, an investigator at The Ohio State University’s Imageomics Institute and a distinguished assistant professor of engineering inclusive excellence in computer science and engineering at Ohio State, gave an in-depth presentation about the latest research advances in the field last month at the annual meeting of the American Association for the Advancement of Science. Chao and two other presenters described how imageomics could transform society’s understanding of the biological and ecological world by turning research questions into computable problems. Chao’s presentation focused on imageomics’ potential application for micro to macro-level problems.Wei-Lun Chao“Nowadays we have many rapid advances in machine learning and computer vision techniques,” said Chao. “If we use them appropriately, they could really help scientists solve critical but laborious problems.” While some research problems might take years or decades to solve manually, imageomics researchers suggest that with the aid of machine and computer vision techniques – such as pattern recognition and multi-modal alignment – the rate and efficiency of next-generation scientific discoveries could be expanded exponentially. “If we can incorporate the biological knowledge that people have collected over decades and centuries into machine learning techniques, we can help improve their capabilities in terms of interpretability and scientific discovery,” said Chao. One of the ways Chao and his colleagues are working toward this goal is by creating foundation models in imageomics that will leverage data from all kinds of sources to enable various tasks. Another way is to develop machine learning models capable of identifying and even discovering traits to make it easier for computers to recognize and classify objects in images, which is what Chao’s team did. “Traditional methods for image classification with trait detection require a huge amount of human annotation, but our method doesn’t,” said Chao. “We were inspired to develop our algorithm through how biologists and ecologists look for traits to differentiate various species of biological organisms.”Conventional machine learning-based image classifiers have achieved a great level of accuracy by analyzing an image as a whole, and then labeling it a certain object category. However, Chao’s team takes a more proactive approach: Their method teaches the algorithm to actively look for traits like colors and patterns in any image that are specific to an object’s class – such as its animal species – while it’s being analyzed. This way, imageomics can offer biologists a much more detailed account of what is and isn’t revealed in the image, paving the way to quicker and more accurate visual analysis. Most excitingly, Chao said, it was shown to be able to handle recognition tasks for very challenging fine-grained species to identify, like butterfly mimicries, whose appearance is characterized by fine detail and variety in their wing patterns and coloring. The ease with which the algorithm can be used could potentially also allow imageomics to be integrated into a variety of other diverse purposes, ranging from climate to material science research, he said.Chao said that one of the most challenging parts of fostering imageomics research is integrating different parts of scientific culture to collect enough data and form novel scientific hypotheses from them. It’s one of the reasons why collaboration between different types of scientists and disciplines is such an integral part of the field, he said. Imageomics research will continue to evolve, but for now, Chao is enthusiastic about its potential to allow for the natural world to be seen and understood in brand-new, interdisciplinary ways. “What we really want is for AI to have strong integration with scientific knowledge, and I would say imageomics is a great starting point towards that,” he said. Chao’s AAAS presentation, titled “An Imageomics Perspective of Machine Learning and Computer Vision: Micro to Global,” was part of the session “Imageomics: Powering Machine Learning for Understanding Biological Traits.”

In the technology landscape, "Data Science" and "Artificial Intelligence" frequently emerge in discussions, sparking curiosity about their similarities and distinctions. Despite appearing alike initially, these two domains embody separate disciplines with distinct aims, approaches, and uses. Grasping the differences between data science and AI — or data science vs artificial intelligence — is vital for harnessing their full potential effectively. This exploration aims to shed light on each field's intricate details and unique characteristics, clearly understanding their respective roles and contributions to the tech landscape.
What Is Data Science?
Data science integrates diverse techniques, algorithms, and methods to derive insights and understanding from both structured and unstructured data. It's a field that spans multiple disciplines, leveraging statistical analysis, machine learning, data mining, and visualization techniques. This approach helps in identifying patterns, trends, and relationships within vast datasets. Data science aims to translate raw data into actionable insights to inform decision-making, drive innovation, and optimize processes across different domains.
Data science combines mathematics, statistics, computer science, and domain expertise to tackle complex analytical problems. Data scientists utilize programming languages such as Python, R, and SQL to manipulate data, build predictive models, and perform statistical analysis. They also employ tools and techniques such as data cleaning, feature engineering, and model validation.
Data science finds applications across diverse industries and sectors, including finance, healthcare, retail, marketing, and manufacturing. In finance, data scientists analyze market trends, customer behavior, and risk factors to inform investment decisions and develop algorithmic trading strategies. Data science is also used for predictive analytics, disease diagnosis, and personalized treatment plans based on patient data and medical records.
Data science is critical in leveraging the vast amounts of data generated in today's digital age to extract valuable insights, drive innovation, and gain a competitive advantage in various fields.
Data Science Applications
Data science applications span various industries and sectors, pivotal in leveraging data to extract insights, drive decision-making, and innovate processes. Here are some key areas where data science finds extensive applications:
1. Business Analytics
Data science is extensively used in business analytics to analyze customer behavior, market trends, and sales forecasts. By mining and analyzing data from various sources, such as customer transactions, social media interactions, and website traffic, organizations can gain valuable insights to optimize strategies, improve customer engagement, and drive revenue growth.
2. Healthcare
Data science has transformative potential in healthcare, where it is utilized for predictive analytics, disease diagnosis, and personalized treatment plans. By analyzing electronic health records (EHRs), medical imaging data, and genomic data, data scientists can develop predictive models to identify at-risk patients, recommend personalized treatment regimens, and improve patient outcomes.
3. Finance
Data science is used in risk assessment, fraud detection, and algorithmic trading in the financial sector. Data scientists can develop models to predict market trends, identify fraudulent activities, and optimize investment strategies by analyzing historical market data, customer transaction patterns, and credit risk factors.
4. Marketing
Data science is crucial in marketing by enabling targeted advertising, customer segmentation, and sentiment analysis. By analyzing customer demographics, purchase history, and online behavior, organizations can tailor marketing campaigns to specific customer segments, identify emerging trends, and measure campaign effectiveness.
5. Manufacturing
Data science is used in manufacturing for predictive maintenance, quality control, and supply chain optimization. By analyzing sensor data from production equipment, data scientists can predict equipment failures before they occur, optimize production processes to minimize defects and optimize supply chain logistics to reduce costs and improve efficiency.
6. Energy
Data science is increasingly used in the energy sector for energy forecasting, demand response optimization, and grid management. Data scientists can develop models to predict energy demand, optimize energy production and distribution, and improve energy efficiency by analyzing historical energy consumption data, weather patterns, and market trends.
7. Transportation
In transportation, data science is used for route optimization, traffic management, and predictive maintenance. By analyzing data from GPS devices, traffic cameras, and vehicle sensors, data scientists can optimize transportation routes to minimize congestion, predict traffic patterns, and identify maintenance needs.
Our Data Scientist Master's Program covers core topics such as R, Python, Machine Learning, Tableau, Hadoop, and Spark. Get started on your journey today!
What Is Artificial Intelligence?
Artificial Intelligence refers to the creation of machines that can imitate human intelligence, allowing them to carry out activities that usually necessitate human cognitive processes. These systems are engineered to replicate behaviors akin to humans, such as learning, solving problems, making decisions, and comprehending natural language. AI aims to develop devices capable of sensing their surroundings, grasping the context, and modifying their behavior independently to fulfill particular goals.
AI encompasses various technologies, including ML, NLP, computer vision, robotics, and expert systems. These technologies enable AI systems to process and analyze large volumes of data, recognize patterns, make predictions, and interact with humans and their surroundings in a human-like manner.
Machine learning, which falls under the broader category of artificial intelligence, concentrates on creating algorithms and models that empower machines to derive knowledge from data and progressively enhance their capabilities without specific programming. Supervised, unsupervised, and reinforcement learning are common approaches used in ML to train models and enable them to perform specific tasks, such as image recognition, language translation, and recommendation systems.
Natural language processing (NLP) is another key component of AI, which involves teaching machines to understand, interpret, and generate human language. NLP enables AI systems to process and analyze text data, extract meaning, and generate responses in natural language, enabling applications like virtual assistants, chatbots, and sentiment analysis.
Computer vision allows machines to perceive and interpret visual information from the environment, such as images and videos. AI-powered computer vision systems can identify objects, recognize faces, detect anomalies, and analyze scenes, enabling applications such as autonomous vehicles, surveillance systems, and medical imaging analysis.
Robotics is another area of AI that focuses on developing intelligent machines capable of performing physical tasks in various environments. AI-powered robots can navigate their surroundings, manipulate objects, and interact with humans and other robots, enabling applications such as industrial automation, healthcare assistance, and search and rescue operations.
Artificial intelligence is revolutionizing numerous industries and sectors by enabling machines to perform tasks that were once exclusive to humans, driving innovation, efficiency, and productivity across various domains. As AI technologies continue to advance, they hold the potential to transform how we work, live, and interact with the world around us.
Artificial Intelligence Applications
Artificial Intelligence (AI) applications are revolutionizing various industries and domains, transforming businesses' operations, enhancing efficiency, and driving innovation. Here are some key areas where AI finds extensive applications:
1. Healthcare
AI revolutionizes healthcare by enabling advanced medical imaging analysis, predictive analytics, and personalized medicine. AI-powered diagnostic systems can analyze medical images such as X-rays, MRIs, and CT scans to assist radiologists in detecting abnormalities and diagnosing diseases accurately. Additionally, AI-driven predictive models can identify at-risk patients, recommend personalized treatment plans, and optimize hospital operations for improved patient outcomes.
2. Finance
In the financial sector, AI is used for algorithmic trading, fraud detection, and risk management. Trading algorithms powered by AI can sift through market data instantaneously, pinpointing opportunities for trades and conducting them swiftly and precisely. Additionally, AI-enhanced systems for detecting fraud can scrutinize transaction data to detect anomalies indicative of suspicious activities, thus preventing fraudulent transactions. This technology is vital in protecting financial institutions and their clients.
3. Customer Service
The emergence of AI has revolutionized customer service by introducing virtual assistants and chatbots. These tools offer tailored support 24/7, engaging with customers in conversational language, addressing questions, solving problems, and independently conducting transactions. This advancement not only enhances customer contentment but also lowers business operational expenses.
4. Marketing
AI reshapes marketing strategies by enabling targeted advertising, customer segmentation, and predictive analytics. AI-driven recommendation engines can analyze customer preferences, purchase history, and online behavior to deliver personalized product recommendations and targeted advertisements, increasing conversion rates and maximizing ROI for marketing campaigns.
5. Autonomous Vehicles
AI drives innovation in the automotive industry by developing autonomous vehicles that can navigate roads, detect obstacles, and make driving decisions autonomously. AI-powered self-driving cars utilize advanced sensors, computer vision, and ML algorithms to perceive their environment, recognize traffic signs, and respond to changing road conditions, enhancing road safety and efficiency.
6. Manufacturing
AI optimizes manufacturing processes by implementing predictive maintenance, quality control, and supply chain optimization solutions. AI-driven predictive maintenance systems can analyze sensor data from production equipment to predict equipment failures and schedule maintenance proactively, thereby minimizing downtime and reducing maintenance costs. Additionally, AI-powered quality control systems can accurately inspect products for defects and deviations from specifications, ensuring product quality and reducing waste.
7. Cybersecurity
Combined with cybersecurity, AI enables threat detection, anomaly detection, and automated incident response. AI-driven cybersecurity solutions can analyze network traffic, identify suspicious activities, and mitigate cyber threats in real-time, protecting organizations from cyberattacks and data breaches.
Become a successful AI engineer with our AI Engineer Master's Program. Learn the top AI tools and technologies, gain access to exclusive hackathons and Ask me anything sessions by IBM and more. Explore now!
Data Science vs Artificial Intelligence: Key Differences
Data science and AI are often used interchangeably but represent distinct fields with different methodologies, objectives, and applications.
DefinitionData Science: Data science is an interdisciplinary field focused on deriving understanding and insights from both structured and unstructured data through a variety of methods, including statistical analysis, machine learning, and data visualization.
Artificial Intelligence: Artificial intelligence involves programming machines to mimic human intelligence, allowing them to undertake activities that usually necessitate human cognitive abilities, including learning, solving problems, and making decisions.
ScopeData Science: Data science focuses on analyzing data to extract insights, identify patterns, and make predictions that can inform decision-making and drive innovation across various domains.
Artificial Intelligence: Artificial intelligence encompasses a broader scope, including developing intelligent systems and algorithms that can perceive their environment, understand context, and make autonomous decisions.
MethodologiesData Science: Data science employs statistical analysis, machine learning, data mining, and data visualization to process and analyze data, uncovering actionable insights and patterns.
Artificial Intelligence: Artificial intelligence employs diverse technologies and approaches, such as machine learning, natural language processing, computer vision, and robotics, to mimic human-like actions and mental processes in machines.
ObjectiveData Science: The primary objective of data science is to extract insights and knowledge from data to drive decision-making, optimize processes, and uncover new opportunities for innovation and growth.
Artificial Intelligence: It develops intelligent systems and algorithms to perform tasks autonomously, make decisions, and adapt to changing environments without human intervention.
ApplicationsData Science: Data science finds applications in diverse industries and sectors, including healthcare, finance, marketing, manufacturing, and transportation. It is used for predictive analytics, customer segmentation, and process optimization.
Artificial Intelligence: Artificial intelligence is applied across various domains, including healthcare, finance, customer service, autonomous vehicles, and cybersecurity. It powers applications such as medical imaging analysis, algorithmic trading, chatbots, self-driving cars, and threat detection.
Data Science vs Artificial Intelligence: Similarities
Here's a comparison table highlighting the similarities between Data Science and Artificial Intelligence:
Aspect
Data Science
Artificial Intelligence
Use of Data
Both involve the analysis of data to extract insights and patterns.
Data is a fundamental component utilized in AI systems for training and decision-making.
Techniques
Both fields employ techniques like machine learning, statistical analysis, and data mining.
AI systems often utilize machine learning algorithms, commonly used in data science for predictive modeling and pattern recognition.
Goal
Both aim to enhance decision-making processes, drive innovation, and optimize operations through data-driven insights.
AI seeks to simulate human-like intelligence in machines to perform tasks autonomously, aligning with data science's broader goal of leveraging data to derive actionable insights.
Applications
They find applications across diverse industries, including healthcare, finance, marketing, and manufacturing.
Both are applied in sectors such as healthcare (e.g., predictive analytics), finance (e.g., algorithmic trading), and marketing (e.g., personalized recommendations).
Interdisciplinary Approach
Both fields are multidisciplinary, drawing from domains such as mathematics, statistics, computer science, and domain expertise.
AI development often involves collaboration between data scientists, computer scientists, and domain experts to develop intelligent systems capable of autonomous decision-making.
Data-Driven Approach
Both rely on a data-centric approach, where insights are derived from analyzing large volumes of data.
AI systems rely on vast amounts of data to train models and make decisions, similar to the data-driven methodologies employed in data science.

As computer vision (CV) systems become increasingly power and memory intensive, they become unsuitable for high-speed and resource deficit edge applications - such as hypersonic missile tracking and autonomous navigation - because of size, weight, and power constraints.At the University of Pittsburgh, engineers are ushering in the next generation of computer vision systems by using neuromorphic engineering to reinvent visual processing systems with a biological inspiration - human vision.Rajkumar Kubendran, assistant professor in Pitt’s Swanson School of Engineering and senior member at the Institute of Electrical and Electronics Engineers (IEEE), received a Faculty Early Career Development (CAREER) award from the National Science Foundation (NSF) for his research on energy-efficient and data-efficient neuromorphic systems. Neuromorphic engineering is a promising frontier that will introduce the next generation of CV systems by reducing the number of operations through event-based computation in a biology-inspired framework.“Dr. Kubendran is one of the pioneers in the new field of neuromorphic, event-driven sensors, algorithms, and processors,” said Dr. Alan George, R&H Mickle Endowed Chair and Professor and Department Chair of Electrical and Computer Engineering at Pitt’s Swanson School of Engineering. “Our department is most excited about his research and growing success in this important field.”While the current computer vision (CV) pipeline allows computers to use cameras and algorithms to enable visual perception, it consumes an overabundance of power and data. Kubendran will use his $549,795 CAREER award to reinvent traditional camera and processing architectures in the CV pipeline by replacing them with biological-inspired sensors, processors, and algorithms. By taking inspiration from biological systems, Kubendran will be able to optimize CV systems by using substantially less power while eliminating a large amount of data transfer.“Humans receive visual stimuli through the retina in our eyes, and that data is sent through the optic nerve to our brain’s visual cortex for visual perception,” Kubendran explained. “The biological vision pipeline is heavily optimized to transfer the least amount of data. If we have retina-inspired camera sensors and visual cortex-inspired processors, then we can train the processors to learn and understand visual scenes and then become capable of versatile spatiotemporal pattern recognition and perception.”Eyes on the FutureKubendran’s project has the potential to lead a transformative and generational shift in today’s society. Critical areas such as healthcare, military defense, Internet of Things (IoT), edge computing, and industrial automation would benefit from event-based CV. “Enabling the use of advanced computer vision on personal electronics can revolutionize our lifestyle through technologies such as self-driving vehicles, always-on smart surveillance, and virtual and augmented reality applications,” Kubendran said. “Bio-inspired vision sensors are predominantly developed by European and Asian companies with no industry or academic contribution from the United States. This project will address that national challenge and provide the U.S. with a leading advantage in the deployment of next-generation computer vision systems.”Kubendran’s research will happen in three simultaneous thrusts. In Thrust One, the research will focus on creating a new class of retina-inspired vision sensors that can outperform existing cameras in terms of features, efficiency, and latency. Thrust Two will focus on the modeling, design, and implementation of scalable corticomorphic networks on hardware. These networks will be tested to examine whether they exhibit nonlinear neuromodulatory dynamics at multiple timescales using mixed feedback control. Thrust Three focuses on the implementation of network architectures and algorithms inspired by neuroscience, such as reinforcement learning and event-based temporal pattern recognition. In addition to the scientific contributions to the CV industry, Kubendran plans to use funding from his CAREER award to develop an educational consortium in the local Pittsburgh community, which will disseminate knowledge gained from the project and train undergraduate students at Pitt as well as students from local high schools to become future neuromorphic and computer vision engineers.
 Computer Vision market
Computer Vision market

Guest Post By Elena AndersonInformation Technology Markets2024-04-01
Technological improvements, such as the integration of algorithms, hardware, and sensors, are driving market expansion. Furthermore, neural networks and convolutional neural networks (CNNs) significantly enhance image identification, object detection, and segmentation capabilities.
IMARC Group's report titled "Computer Vision Market Report by Component (Hardware, Software), Product Type (Smart Camera-based, PC-based), Application (Quality Assurance and Inspection, Positioning and Guidance, Measurement, Identification, Predictive Maintenance, 3D Visualization and Interactive 3D Modelling), Vertical (Industrial, Non-Industrial), and Region 2024-2032". The global computer vision market size is expected to exhibit a CAGR of 6.39% during 2024-2032.
For an in-depth analysis, you can refer sample copy of the report: www.imarcgroup.com/compute…uestsample
Factors Affecting the Growth of the Computer Vision Industry:Technological Advancements:
Technological advancements such as integration of algorithms, hardware, and sensors are fueling the market growth. Additionally, neural networks and convolutional neural networks (CNNs) greatly improve image recognition, object detection, and segmentation capabilities. These advancements allow computer vision systems to perform tasks with high precision and expand their applications across industries. Additionally, faster and more performant hardware, such as graphics processing units (GPUs) and specialized processors, play a critical role in handling the computational requirements of complex computer vision tasks. Additionally, advances in sensors such as high-resolution cameras and LiDAR (light detection and ranging) contribute to improved data collection and image quality.Rising Demand for Automation:
Increasing demand for automation across industries is supporting the market growth. Additionally, automation offers many other benefits, including increased efficiency, reduced operating costs, and improved quality control. Moreover, computer vision technology plays a pivotal role in enabling automation by giving machines the ability to understand and respond to visual information. In the manufacturing sector, computer vision systems are used for quality inspection and defect detection on assembly lines. They identify defects in products with high speed and accuracy, ensuring that only high-quality products reach individuals.Growth in AI and ML Learning:
Artificial intelligence (AI) and machine learning (ML) algorithms in computer vision allow you to learn, adapt, and make improved decisions based on visual data. Additionally, AI and ML-based computer vision systems are increasingly being used in applications such as self-driving cars, which interpret sensor data from cameras and LiDAR to make real-time driving decisions. Additionally, in the retail field, AI-based recommendation engines provide personalized shopping experiences by analyzing individual behavior and preferences based on visual data.
Leading Companies Operating in the Global Computer Vision Industry:Basler AG
Baumer Optronic
CEVA Inc.
Cognex Corporation
Intel Corporation
Jai A/S
Keyence Corporation
Matterport Inc.
Microsoft Corporation
National Instruments
Sony Corporation
Teledyne Technologies Inc.
Ask Analyst for Sample Report: www.imarcgroup.com/request…amp;flag=C
Computer Vision Market Report Segmentation:
By Component:Hardware
Software
Hardware represented the largest segment as it captures, processes, and interprets visual data.
By Product Type:Smart Camera-based
PC-based
PC-based accounted for the largest market share due to their rising utilization among researchers, developers, and engineers to experiment with different computer vision algorithms.
By Application:Quality Assurance and Inspection
Positioning and Guidance
Measurement
Identification
Predictive Maintenance
3D Visualization and Interactive 3D Modelling
Quality assurance and inspection holds the biggest market share on account of the increasing need to examine products and materials for defects, inconsistencies, or deviations.
By Vertical:Industrial
Non-Industrial
Industrial exhibits a clear dominance in the market as it enhances efficiency, quality control, and automation.
Regional Insights:North America: (United States, Canada)
Asia Pacific: (China, Japan, India, South Korea, Australia, Indonesia, Others)
Europe: (Germany, France, United Kingdom, Italy, Spain, Russia, Others)
Latin America: (Brazil, Mexico, Others)
Middle East and Africa
Asia Pacific enjoys the leading position in the computer vision market on account of the rising need for image and video processing applications in various industries.
Global Computer Vision Market Trends:
The increasing number of digital images and videos on the Internet along with the rise in Internet of Things (IoT) devices and surveillance systems presents a positive market outlook. Accordingly, this massive amount of data provides ample opportunities for the development and training of computer vision models, making them more powerful and capable. Strict regulations and requirements related to safety, security, and privacy are supporting the market growth. In addition to this, increasing adoption of computer vision in the financial sector for fraud detection and identity verification is fueling the market growth.